TRIE (트라이) 자료구조
10 May 2019
이번 포스팅에서는 자연어처리에서 자주 사용되는 자료구조 중 하나인 trie에 대해서 알아보겠습니다.
TRIE(트라이)란?
TRIE는 문자열을 효율적으로 검색하기 위해 고안된 자료구조입니다.
TRIE는 검색(reTRIEve)이라는 단어에서 유래되었으며 유래에서 알 수 있듯이 검색엔진 또는 자연어처리 등과 같이 문자열을 빠르게 탐색해야 하는 분야에서 다양하게 사용되고 있습니다.
TRIE 자료구조
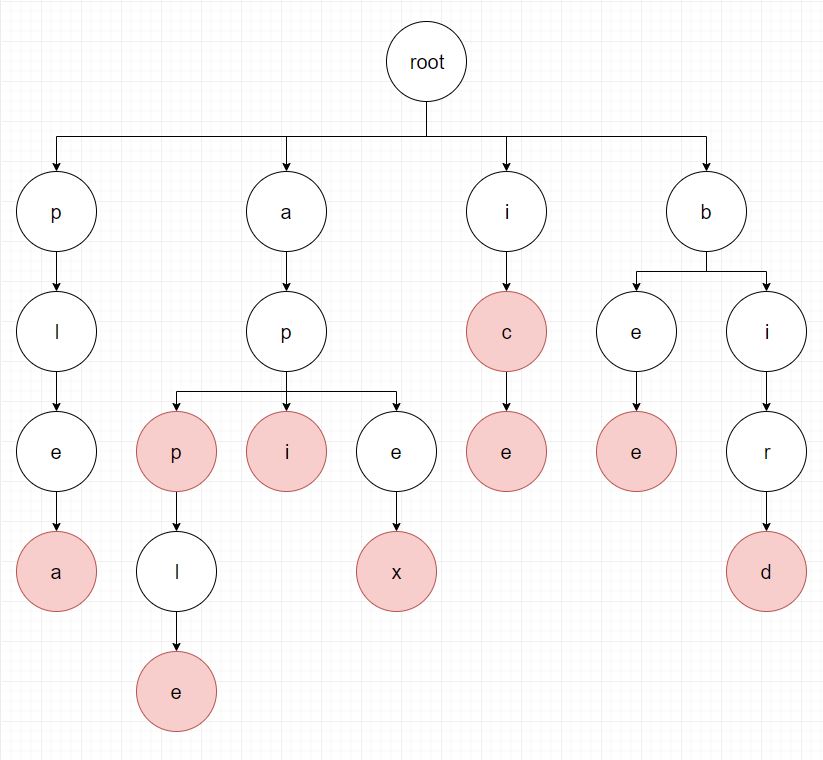
TRIE는 트리 기반의 자료구조로써 저장할 단어를 각각의 문자로 쪼개어 아래 그림과 같이 트리를 구성하게 됩니다.
이 때 단어의 마지막 문자에는 단어의 끝을 나타내는 표시를 해줍니다.
아래 TRIE는 apple, app, api, apex, ice, ic, bee, bird, plea의 단어로 구성된 TRIE 입니다.
TRIE 검색
문장 appleapi에 포함된 모든 단어를 찾는 문제로 가정해보겠습니다.
이 때 답은 apple, app, api, plea 입니다.
먼저 appleapi에서 첫번째 문자인 a를 root의 자식 노드들에서 검색합니다.
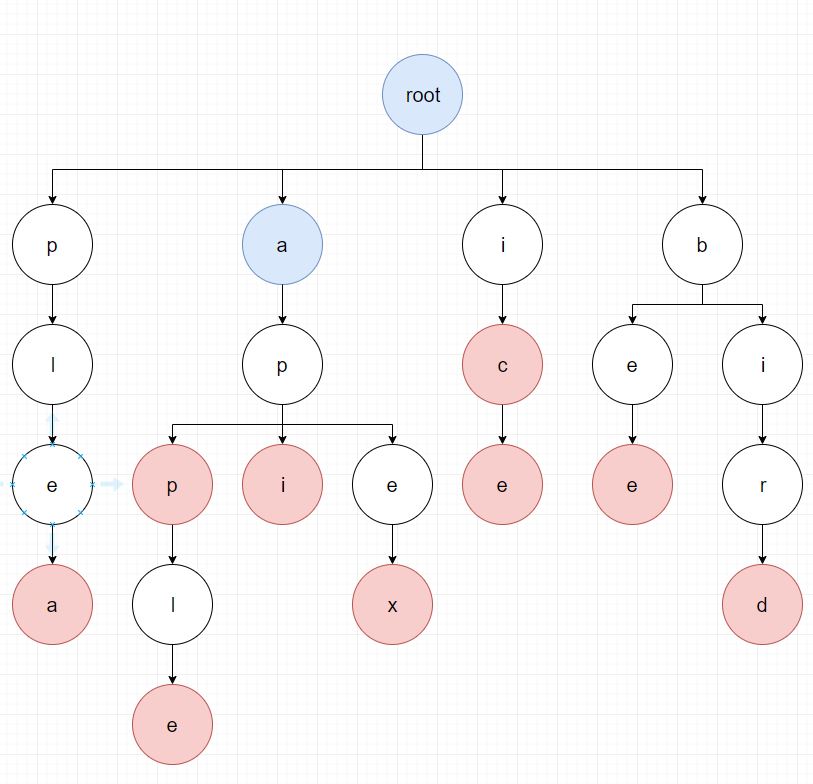
위와 같이 검색이 되고, 다시 검색된 노드의 자식 노드들 중에서 다음 문자인 p를 검색합니다.
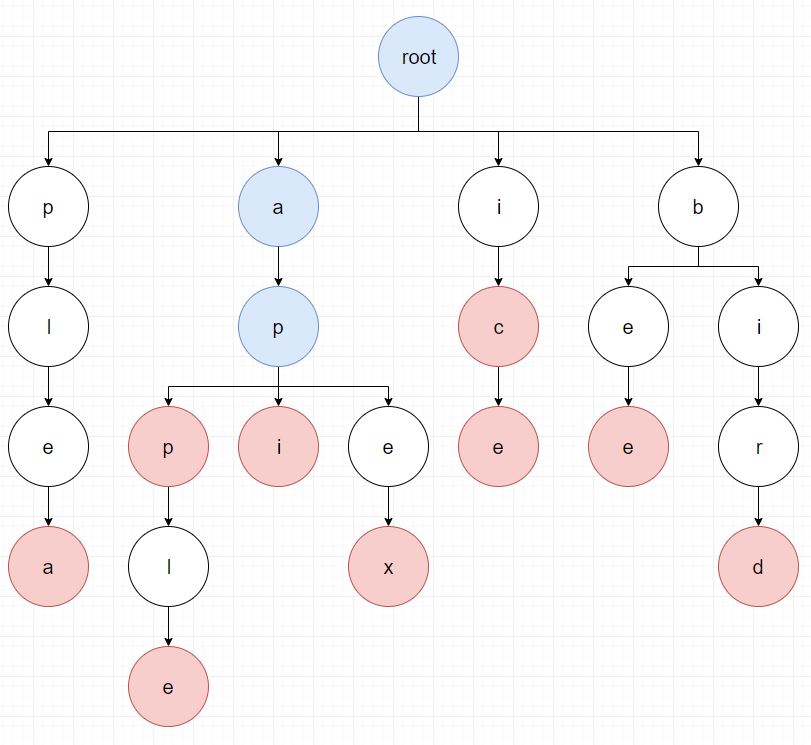
이런식으로 주어진 문장을 끝까지 검색하면 아래 그림과 같이 apple, app이 검색됩니다.
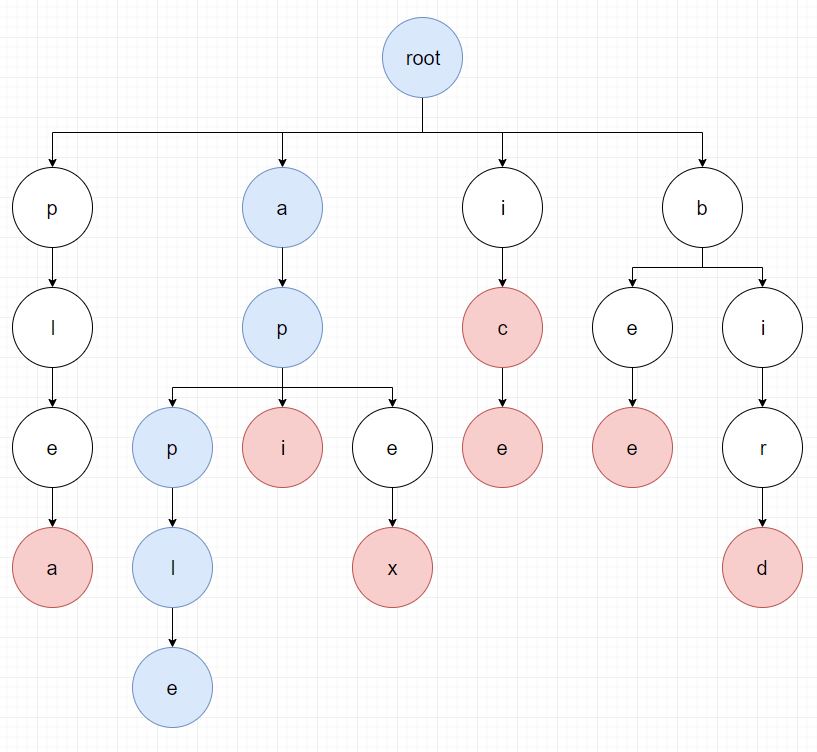
주어진 문장 appleapi에서 첫번째 문자인 a에 대한 탐색은 마쳤습니다.
이어서 다음 문자인 p를 다시 root의 자식 노드들에서 검색합니다.
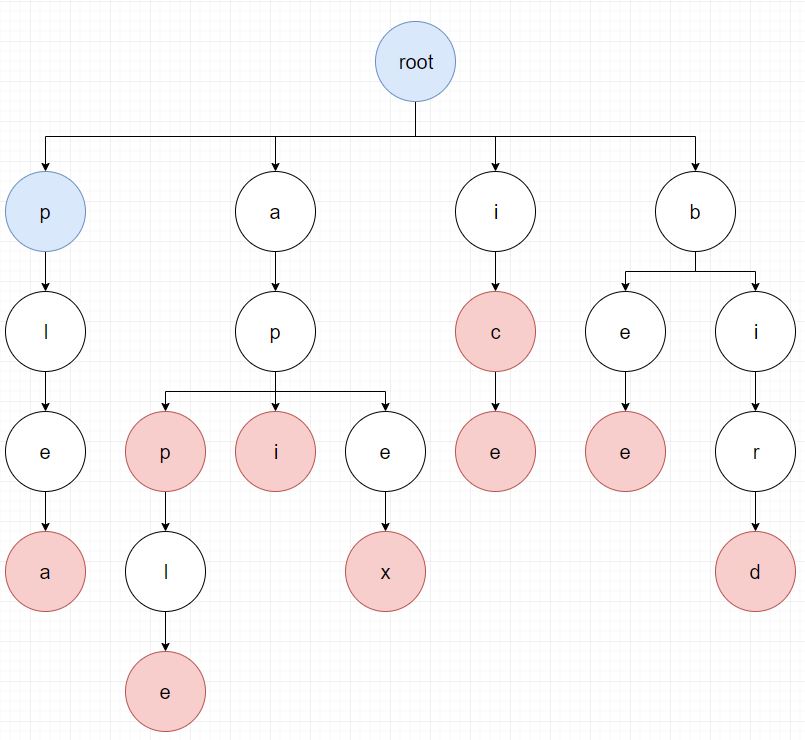
검색된 노드의 자식 노드들 중에서 다음 문자인 p를 검색해봅니다.
이 때 자식 노드들 중에서 p가 없기 때문에 입력된 문장의 두번째 문자 p에 대한 탐색은 종료됩니다.
다음으로 세번재 문자인 p에 대해서 검색을 합니다.
위와 같은 방법으로 검색을 하게되면 아래 그림과 같이 plea가 검색됩니다.
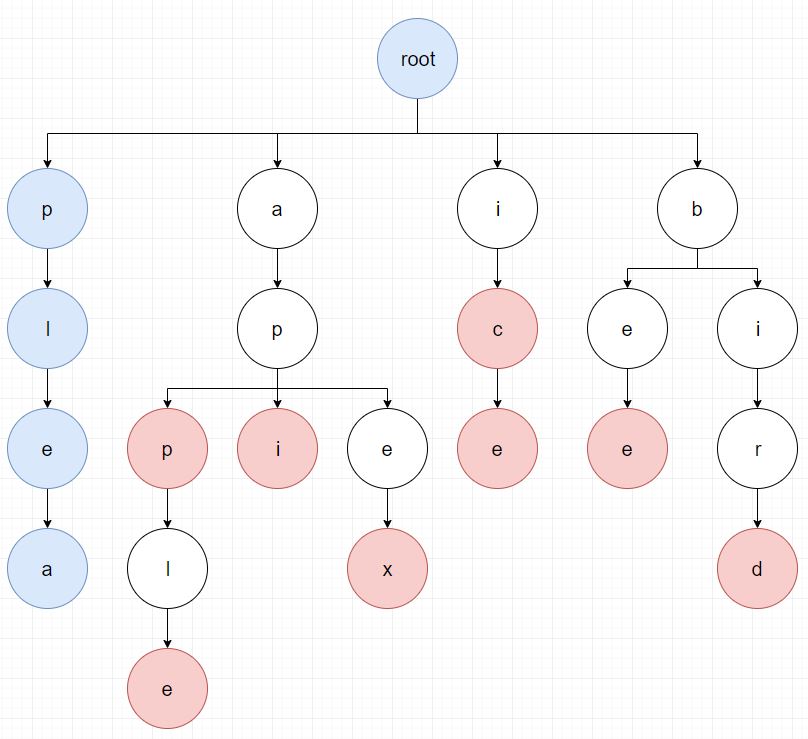
네번째 문자 l과 다섯번째 문자 e는 root의 자식 노드에 없기 때문에 바로 종료됩니다.
여섯번째 문자인 a에 대해서 다시 검색을 하게 되면 아래 그림과 같이 api가 검색됩니다.
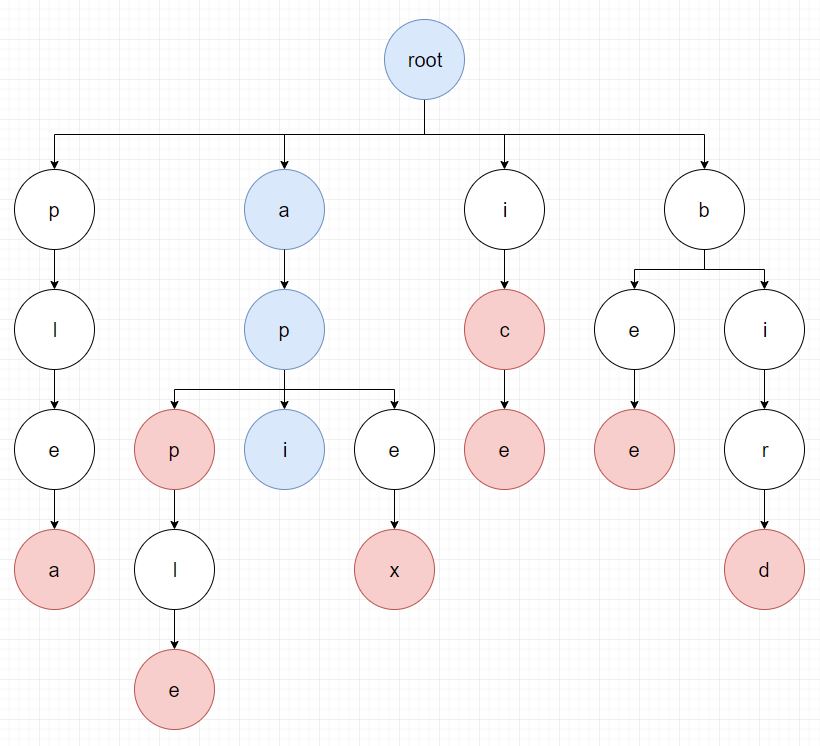
남은 문자인 p, i에 대해서는 검색되는 단어가 없습니다.
최종적으로 appleapi에서 검색된 문자는 apple, app, plea, api가 됩니다.
TRIE를 왜 쓰나요?
가장 빠른 알고리즘은 hash를 이용한 방법일 겁니다.
주어진 문장을 잘게 쪼갠 후 hash 값을 통해서 사전에 포함된 단어를 찾아야 합니다.
그러나 이 때 주어진 문장을 잘게 쪼갠 후의 과정이 있기 때문에 빠르게 단어를 찾을 수 없습니다.
또한 위 예제의 경우에는 사전에 포함된 단어의 개수가 얼마되지 않기 때문에 다른 알고리즘을 통해서 더 빠르게 포함된 단어를 찾을 수도 있습니다.
그러나 사전의 사이즈가 매우 커지면 빠르게 단어를 찾을 수 없습니다.
그렇기 때문에 TRIE를 통해서 이러한 문제를 해소할 수 있습니다.
TRIE는 어디에 쓰이나요?
가장 대표적으로 shineware에서 오픈소스로 공개한 KOMORAN에도 TRIE 기반의 자료구조가 사용되고 있습니다.
영어는 띄어쓰기 단위로 단어를 인지할 수 있지만 한국어의 경우에는 하나의 어절에 여러 형태소가 포함될 수 있습니다.
이러한 여러 형태소를 찾아야하는 문제라면 위에서 설명한 것과 같이 TRIE가 적합합니다.
또한 자동완성과 같은 prefix 검색에도 사용할 수 있습니다.
위 예제의 경우에서는 ap 까지만 검색하더라도 app, apple 을 자동완성 시킬 수 있습니다.
이 때 노드에 가중치를 주어서 자동완성에 노출될 단어의 순위를 조절할 수도 있습니다.
이 외에도 텍스트를 필요로 하는 다양한 분야에서 사용이 가능합니다.
단점
이러한 TRIE에도 단점이 몇 가지 있습니다만, 가장 큰 단점은 exact matching에 취약합니다.
만약에 사전에 매우 긴 단어가 있고 주어진 단어가 사전에 있는지 확인하기 위해서는 꽤 많은 depth로 들어가게 되고 검색 속도가 저하될 수 있습니다.
Exact matching의 경우에는 TRIE 보다는 다른 자료구조 및 알고리즘을 사용하는 것이 좋습니다.
지금까지 TRIE에 대해서 간략하게 살펴봤습니다.
본 글에서 설명한 TRIE는 기본적인 형태의 TRIE이기 때문에 실제 서비스나 제품을 개발하는데 있어서는 조금 더 개선될 방법들을 적용해야하는 경우가 많습니다.
TRIE 자료구조에서 탐색 속도를 높이기 위해서 제안된 Aho-corasick이라는 알고리즘이나 메모리 효율을 높이기 위해서 제안된 Radix 트라이 등도 있습니다.
오늘 살펴본 TRIE에 대해서 대략적으로 이해하고 있다면 다양한 trie들을 이해하는데 큰 무리가 없을 것입니다.